Appendix 1 - Introduction to NONMEM, PREDPP, and NM-TRAN
This chapter introduces a computer program called NONMEM. It also introduces two programs that are distributed with NONMEM and make it easier to use: PREDPP and NM-TRAN.
NONMEM stands for "Nonlinear Mixed Effects Model." NONMEM is a computer program, written in FORTRAN 77, designed to fit general statistical (nonlinear) regression-type models to data.
NONMEM was developed by the NONMEM Project Group at the University of California at San Francisco for analyzing population pharmacokinetic data in particular. These are data typically collected from clinical studies of pharmaceutic agents, involving the administration of a drug to individuals and the subsequent observation of drug levels (most often in the blood plasma). Proper modeling of these data involves accounting for both unexplainable inter- and intra-subject effects (random effects), as well as measured concomitant effects (fixed effects). NONMEM allows this mixed effect modeling. Such modeling is especially useful when there are only a few pharmacokinetic measurements from each individual sampled in the population, or when the data collection design varies considerably between these individuals. However, NONMEM is a general program which can be used to fit models to a wide variety of data.
Like many nonlinear regression programs, NONMEM does not have any "built in" models (such as the linear model) with which it can compute a predicted value given the current values of the regression parameters. Instead, NONMEM calls a subroutine having entry name PRED ("prediction") to obtain a predicted value. PRED also must compute for NONMEM partial derivatives with respect to certain random variables. Depending on the model and the kinds of doses, PRED may be very simple or may be very complicated. A user can write his own PRED subroutine. This can be as simple or complicated as is necessary, and may involve calls to its own subprograms.
PREDPP stands for "PRED for Population Pharmacokinetics". It is a PRED subroutine for use with NONMEM and is the second major component distributed with NONMEM. Whereas NONMEM is a general nonlinear regression tool, PREDPP is specialized to the kinds of predictions which arise in pharmacokinetic data analysis. It can compute predictions according to many different pharmacokinetic models, according to a great variety of dosing regimens. Almost all the examples in this guide use PREDPP.
NM-TRAN stands for "NONMEM Translator". It is the third major component distributed with NONMEM. It is a separate, "stand-alone" control language translator and data preprocessor. When NM-TRAN is used, a NONMEM run includes two separate steps: first the NM-TRAN step, in which a file of NM-TRAN records (which begin with "$") are translated into several NONMEM input files, and second the NONMEM step itself. All the examples in this guide use NM-TRAN. We strongly recommend its use.
Note that neither NM-TRAN nor NONMEM-PREDPP run interactively. Files of commands and data are created by means of (say) the operating system editor. Then NM-TRAN and NONMEM are executed, using these files as input. Figure 1.1 shows the relationship between NONMEM, PREDPP, and NM-TRAN.
In this section we discuss the components of NONMEM in some detail.
NONMEM is written (almost) entirely in ANSI FORTRAN 77 (American National Standard Programming Language X3.9-1978). It is distributed on magnetic tape or micro floppy disks as FORTRAN source code. It can be compiled and run on any computer which has a FORTRAN 77 compiler and sufficient memory and speed to run a large, computationally intensive program. It is currently installed at over 400 sites on computers ranging in size from personal computers to supercomputers. Minor changes are sometimes necessary to the source code to specialize NONMEM to a particular computer or operating system. The requirements and changes are documented in NONMEM Users Guide Part III.
NONMEM consists of a main program and many subroutines, all of which are required for each NONMEM run. As discussed above, one subroutine, PRED, is not included in NONMEM itself.
PREDPP is not a single subroutine. It is a collection of FORTRAN subroutines. Some of these are always needed but must be supplied by the user himself (see PK and ERROR below). Others are always needed and are supplied; these are called the kernel routines. Others (subroutines ADVAN and TRANS, for example) are also always needed, and are supplied, but are chosen from different versions corresponding to different pharmacokinetic models. The collection of supplied routines constitutes the PREDPP Library.
Two very important subroutines of PREDPP are called PK and ERROR. PK computes the values of the population or individual pharmacokinetic parameters (e.g., CL and V) of a given model and accounts for the "differences" between individual and population values. ERROR accounts for the "differences" between predicted and observed values. These two subroutines are where the basic task of modelling is carried out; this task is the user’s responsibility.
Figure 1.2 shows the major components of PREDPP.
Whether PREDPP is used or a special purpose PRED subroutine is written, the PRED subroutine must be combined ("linked") with NONMEM; this process (which is sometimes is called "link editing" or "loading") must take place before the actual NONMEM run. The NONMEM-PRED combination is generally called a "load module" or "executable module". Compiling and linking are processes which are operating system dependent; each installation must supply its own commands and procedures for these tasks. They may be done before the NM-TRAN step or between it and the NONMEM step.
NM-TRAN provides the following services: control language translation, model specification via FORTRAN-like statements (called abbreviated code), partial differentiation, and preprocessing of the data. They are discussed separately.
NM-TRAN includes a language for communicating control information to NONMEM. NM-TRAN records are free-form (i.e., spacing between options within a record and the order of the records and their options is flexible) and use English words (or their abbreviations) for options. For example, the record name $ESTIMATION may be abbreviated to $EST; the option name SIGDIGITS may be abbreviated to SIG. Either spaces or commas may be used to separate options. Defaults are understood for most options, allowing the records to be relatively compact. Considerable error checking is performed by NM-TRAN. This reduces the number and severity of the errors that can occur during the NONMEM run.
NM-TRAN translates a file of NM-TRAN control records into NONMEM control records, which use a fixed-field, predominately numerical control language.
With PREDPP, FORTRAN subroutines PK and ERROR are needed to specify parts of the pharmacostatistical model. In most cases, these specifications can be directly expressed within NM-TRAN records $PK and $ERROR, using FORTRAN-like assignment and conditional statements called abbreviated code. These statements can be implemented by NM-TRAN in either of two ways†: ----------
1) Generated Subroutines NM-TRAN can generate complete FORTRAN subroutines, incorporating the abbreviated code. An intermediate step between the NM-TRAN and NONMEM steps is needed to compile these subroutines and link them with NONMEM-PREDPP. Although NN-TRAN provides a report file listing the required subroutines to be linked together, it is the user’s responsibility to provide the necessary operating system control commands to perform compilations and linking. All examples in this guide will produce generated subroutines. Figure 1.3 shows how the compile and link step relates to the two steps of Figure 1.1.
2) Library Subroutines NM-TRAN comes with a library of general-purpose PK and ERROR ( and other) subroutines. NM-TRAN can generate a file of instructions to these subroutines which tells them how to perform the requested computations. When they are used, the intermediate "compile and link" step is not required; for a given ADVAN and TRANS, the same NONMEM-PREDPP load module can be used for all $PK and $ERROR records. Figure 1.4 shows how library subroutines are used.
Figure 1.4. A NONMEM-PREDPP run that includes NM-TRAN library subroutines. If the user supplies complete PK and ERROR subroutines (i.e., $PK and $ERROR records are not used), then the NONMEM load module can be built at any time.
Note that even when PREDPP is not used, the same options exist. For example, if the desired model can be expressed via a $PRED record, then NM-TRAN can either generate a complete PRED subroutine or a file of instructions to the NM-TRAN library PRED subroutine. However, whereas NM-TRAN’s FORTRAN-like syntax is sufficient for most purposes of writing PK and ERROR subroutines, it is not sufficient for writing any but the simplest of PRED subroutines.
NONMEM requires that PRED (whether PREDPP or
user-written) compute more than just predicted values. It
must also compute certain partial derivatives with respect
to the random variables 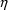 and
and
 . When $PK, $ERROR, or $PRED
records are used, NM-TRAN performs symbolic differentiation
to generate the code (or instructions to NM-TRAN Library
routines) needed to compute these derivatives. This relieves
the user of a major burden.
. When $PK, $ERROR, or $PRED
records are used, NM-TRAN performs symbolic differentiation
to generate the code (or instructions to NM-TRAN Library
routines) needed to compute these derivatives. This relieves
the user of a major burden.
NM-TRAN includes a Data Preprocessor program which allows the user greater flexibility in constructing his data file than is allowed in a data file input directly into NONMEM.
TOP TABLE OF CONTENTS NEXT APPENDIX ...